
Mis à jour le 31/03/2025
On appelle Googlebot le programme informatique chargé de parcourir les pages du world wide web afin d’en permettre l’indexation par le célèbre moteur de recherche. Ces robots (ou bots) sont plusieurs milliers à sillonner internet. Ils appartiennent à la famille des crawlers (ou spiders), qu’utilisent également certains outils SEO, comme Oncrawl, pour parcourir et analyser des sites web.
C’est grâce à ces robots d’exploration que Google et les autres moteurs de recherche (Bing, Yandex, Baïdu, etc.) accumulent des données et trient les ressources du net pour ensuite les invoquer dans leurs pages de résultats (ou SERP).
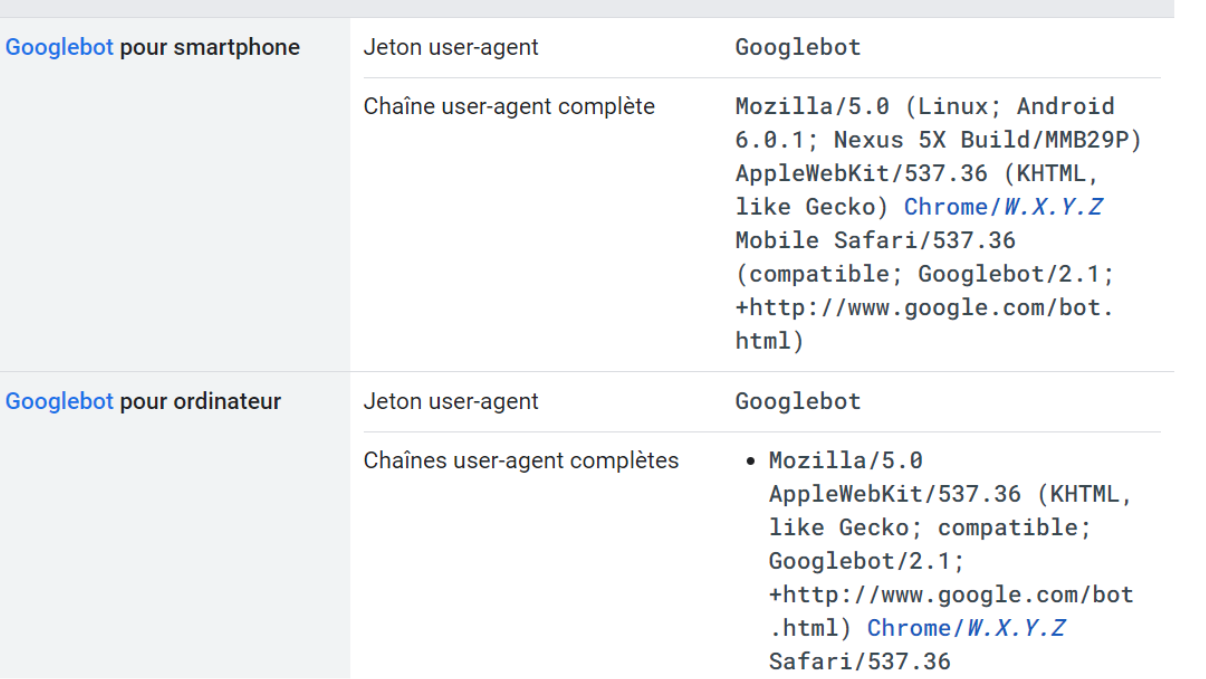
Nota Bene : les Googlebots se divisent en deux catégories, à savoir ceux qui simulent la navigation d’un internaute sur ordinateur, et ceux qui crawlent les sites comme sur appareil mobile.
Quel est le rôle d’un Googlebot ?
Tout au long de son cheminement ultra-rapide, un Googlebot va permettre d’analyser la structure et le contenu des sites web qu’il visite (fichiers HTML, CSS, médias utilisés, etc.).
Son but est de miner un maximum de données à transmettre aux robots indexeurs, mais également de repasser par les mêmes sites afin de rester à jour, sans pour autant surcharger la bande passante des serveurs.
C’est donc de ce seul processus que dépend l’entièreté du fonctionnement des moteurs de recherche.
Comment fonctionnent les Googlebots ?
Les Googlebots ne parcourent pas les sites bloc par bloc, mais font des allées et venues en ne visitant que quelques pages à la fois. Pour chaque page crawlée, il récupère le code source HTML et le transfère au moteur de recherche. Il analyse également la structure du site internet, via le maillage interne et les balises title, Hn, Alt, etc. afin de mieux se diriger sur le domaine qu’il visite.
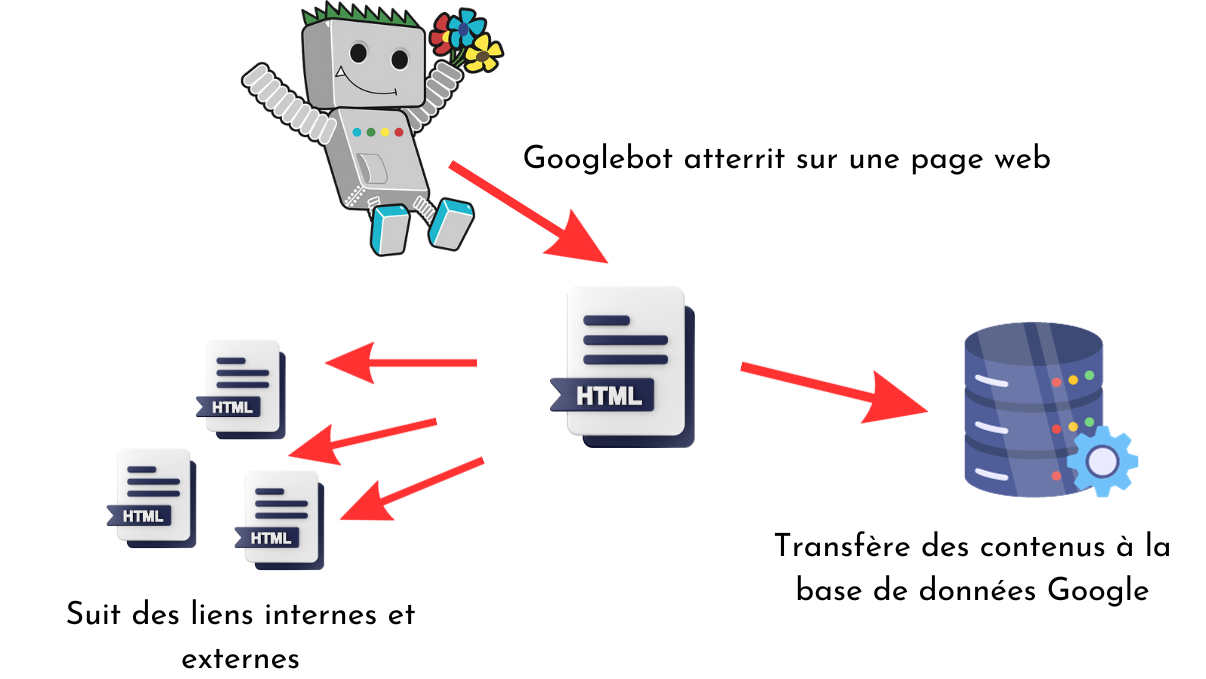
Pour passer d’une page à l’autre, il va tout simplement suivre les liens de redirection, simulant la navigation d’un internaute. Normalement, il ne suit que les hyperliens dofollow, qu’ils soient internes ou externes. Le processus se renouvelle à chaque URL visitée, et les spiders établissent des rapports de cohérence entre les pages d’un même site ou de plusieurs domaines qui se renvoient les uns vers les autres, de manière plus ou moins pertinente selon le contexte de la redirection.
Nota Bene : en arrivant sur un domaine, avant de poursuivre sa navigation, le Googlebot vérifie le fichier robots.txt, conçu pour donner quelques indications de crawl. De cette manière, il se dirigera de préférence sur les pages que le webmaster cherche à faire indexer en priorité.
Quelle est la fréquence de passage des Googlebot sur un domaine ?
Les bots de Google ne passent pas à la même fréquence d’un site à l’autre. Celle-ci peut varier de quelques minutes à quelques jours selon :
- la taille du domaine, autrement dit le nombre de pages qu’il contient ;
- la profondeur maximum du site web : les crawlers s’aventurent moins souvent sur les pages accessibles via un grand nombre de clics ;
- la périodicité de ses mises à jour ; plus elles sont fréquentes, plus les crawlers viendront s’enquérir des changements ;
- la qualité des contenus.
Ces critères vont également déterminer le budget crawl alloué à chaque domaine. En effet, Google va consacrer davantage de “temps machine” aux sites qui lui semblent valoir le coup.
Quoi qu’il en soit, vous pouvez connaître la fréquence et la date des derniers passages sur votre site internet via la Google Search Console, dans la section “Couverture”. À cet égard, les analyses de log sont encore plus précises, au moyen d’outils comme Oncrawl, Scraming Frog ou encore Deepcrawl.
Que peut-on optimiser pour favoriser le passage des Googlebots sur un site web ?
Pour que vos pages soient crawlées le plus régulièrement possible, et donc réévaluées par les bots de Google, il convient de :
- bâtir une arborescence de site claire, cohérente et équilibrée en termes de profondeur ;
- travailler le maillage interne ;
- surveiller la vitesse de chargement de vos pages et autres performances techniques de votre site web ;
- publier de nouveaux contenus et les mettre à jour régulièrement ;
- traquer les duplicate contents, qui empêchent les bots de s’intéresser à vos pages ;
- avoir un site responsive pour l’index mobile-first, en activité depuis novembre 2018.
Outre les optimisations on-page, vous pouvez vous adresser directement aux bots, grâce à des manipulations techniques relativement simples mais résolument indispensables !
Avoir un fichier sitemap.xml à jour
Le sitemap.xml consiste en une liste répertoriant toutes les pages de votre site web. Il donne aux spiders diverses informations sur l’architecture du site et l’ensemble du réseau formé par votre maillage interne. Plus votre site contient de pages, plus le sitemap est important.
En effet, pour les crawlers, c’est un peu l’équivalent d’un plan de métro, lequel indique à la fois les lignes à emprunter, mais également les lieux importants situés à proximité d’une station. Les Googlebots parviennent donc à mieux s’orienter en consultant la sitemap, notamment lorsqu’il y a des modifications de contenu à répertorier.
Il est possible de soumettre directement votre sitemap.xml à Google, toujours via la Search Console. Cela permet de tenir le moteur de recherche informé de toutes les pages fraîchement ajoutées ou corrigées. Les crawlers n’auront qu’à consulter le sitemap pour ouvrir instantanément n’importe quelle page de votre site !
Jouer sur le comportement des Googlebots avec des fichiers robots.txt
Afin d’optimiser le budget crawl de votre site web, vous pouvez bloquer l’accès à certaines pages obsolètes ou en chantier. De cette manière vous évitez les mauvais signaux SEO, comme les contenus de faible qualité par exemple.
Pour bien utiliser les fichiers robots.txt il existe quelques commandes importantes à connaître telles que :
- disallow, qui fonctionne aussi pour les autres bots que ceux de Google, bloque momentanément l’accès à certaines pages où à l’ensemble de votre site web ;
- nofollow, qui demande aux bots de ne pas suivre les hyperliens (et donc de ne pas distribuer de linkjuice à la page vers laquelle pointe la redirection) ;
- noimageindex, qui indique aux crawlers de ne pas indexer certaines images et ainsi de ne pas les faire apparaître dans les SERPs.
Nota Bene : attention à ne pas bloquer l’accès aux fichiers JS et CSS, essentiels pour que les Googlebots parviennent à interpréter correctement le contenu des pages web.
Pour finir…
Les Googlebots sont en fait des crawlers (ou spiders) essentiels au fonctionnement des moteurs de recherche. Il est possible de les inciter à passer le plus souvent possible sur votre domaine afin de transmettre vos mises à jour au moteur de recherche et donc redistribuer les cartes SEO à votre avantage.
N’hésitez pas, par ailleurs, à utiliser des commandes tels que le sitemap.xml et le robots.txt, pour rentabiliser votre budget crawl et éviter de laisser passer des signaux négatifs pour votre référencement.
Enfin, si vous possédez un site de moyenne ou grande taille, vous aurez sans doute besoin des services d’une agence SEO pour réaliser tous les efforts d’optimisation nécessaires à la bonne indexation et au ranking de vos pages web. Pour aller plus loin, n’hésitez pas à visionner la vidéo ci-dessus !
