
Mis à jour le 02/04/2025
On appelle “indexation” le processus consistant à parcourir le web, afin d’en analyser, répertorier les ressources, avant de les classer dans les pages de résultats de recherche en fonction des mots-clés saisis par les internautes. Une phase donc absolument nécessaire au sein du référencement naturel (et même payant…).
En effet, une page web ne faisant pas partie de l’index d’un moteur de recherche réduit drastiquement ses chances d’être consultée, car il faudra alors en connaître l’URL exacte et la taper directement dans le navigateur pour la trouver – ce que les moteurs de recherche sont justement censés nous dispenser d’avoir à faire…
Qu’est-ce que l’index d’un moteur de recherche exactement ?
Un index en informatique, c’est tout simplement une base de données qui permet de ranger une somme astronomique de fichiers afin de les retrouver quasi instantanément et de les mettre à disposition dès que nécessaire.
En d’autres termes, c’est un peu comme une bibliothèque invisible qui crée à la demande des rayons infinis de documents classés par ordre de pertinence (et non pas par simple ordre alphabétique !).

Les moteurs de recherche (Yandex, Bing, Google) possèdent donc tous un index dans lequel est stockée une copie d’une partie du world wide web. L’index de Google est le plus conséquent, avec 100 millions de gigaoctets de données pour plusieurs centaines de milliards de pages individuelles.
Nota Bene : l’index sert évidemment de référence afin d’identifier rapidement les nouvelles ressources publiées quotidiennement sur le web et de se mettre à jour en permanence.
Comment fonctionne l’indexation des moteurs de recherche ?
Le processus d’indexation se décline en trois étapes, détaillées ci-dessous.
1. Le crawl des robots d’exploration
Les robots d’exploration, ou crawlers pour les intimes, sont les algorithmes chargés de parcourir indéfiniment l’immense toile d’internet afin de remplir et corriger l’index de leur moteur de recherche.
C’est donc une armée de Googlebots, Bingbots, etc., qui parviennent à crawler plusieurs dizaines de milliards d’URL/jour !
Lorsqu’un bot arrive sur une page, il analyse son contenu et poursuit son chemin à travers tous les liens qui s’y trouvent. De cette manière, il se déplace de page en page à récolter des données sans arrêt, puis revient périodiquement sur les sites déjà indexés, tel un nageur infatigable.
2. La copie des contenus
Au cours de leur périple, les crawlers effectuent la copie automatique de toutes les ressources pertinentes et indexables. Cela consiste à récupérer le code HTML de chaque page avant de le transmettre à l’index du moteur de recherche. À l’intérieur de ce code se trouvent tous les éléments nécessaires à la catégorisation du contenu de chaque document à indexer.
3. Le stockage des contenus
Toutes les données ainsi récoltées par les crawlers sont stockées sur des millions de serveurs répartis dans plus d’une vingtaine de datacenters disséminés sur les différents continents.
Nota bene : l’index des moteurs de recherche ne représente pas l’entièreté d’internet. De nombreuses pages non indexables ou tout simplement bannies n’y figurent pas ! Cet ensemble de pages plus difficilement accessibles est appelé “deep web”, lequel contient les fameux réseaux du dark web.
Combien de temps prend l’indexation ?
Tout dépend de nombreux critères, comme le nombre de publications ajoutées par jour ou par semaine, la notoriété d’un site ou encore simplement la vitesse de chargement. Dans le meilleur des cas, les nouveaux contenus seront publiés au bout d’un ou deux jours. Les indexations les plus lentes prendront plus d’une ou deux semaines.
Indexation : quels leviers SEO ?
Vous l’aurez compris, sans une bonne indexation de toutes les pages importantes de votre site web, votre stratégie SEO n’ira pas chercher bien loin. La bonne nouvelle, c’est qu’on peut commencer le travail d’optimisation dès ce stade, afin de :
- choisir les pages à indexer ou non ;
- augmenter la vitesse d’indexation ;
- bien exploiter son budget crawl ;
- augmenter la fréquence de crawl ;
C’est quoi, le budget Crawl ?
Le Budget Crawl, c’est le nombre de pages explorées par les bots des moteurs de recherche chaque fois qu’ils passent par votre site internet. Il est donc important de ne pas le gaspiller, surtout si votre fréquence de crawl (nombre passage sur votre domaine sur une période donnée) est basse.
Les crawlers déterminent le budget et la fréquence de crawl en fonction d’un certain nombre de critères, à savoir :
- la taille et l’ancienneté du site ;
- les performances du serveur qui héberge le site ;
- la profondeur de son arborescence ;
- la fréquence de mise à jour ;
- etc.
En résumé, le but est de faire indexer vos pages web le plus souvent possible, le plus rapidement possible et en évitant les contenus inutiles.
Comment optimiser l’indexation d’un site web ?
Il existe plein de manières d’aider les bots pour faire indexer votre site web dans les meilleures conditions. Nous avons rangé les possibilités par ordre de difficulté technique.
- produire régulièrement du contenu optimisé pour inciter les bots à revenir plus souvent ;
- travailler votre maillage interne pour favoriser l’exploration des crawlers, lesquels pourront suivre vos liens pour faire le tour de votre domaine. Profitez-en pour placer dans votre les menus header et footer les pages les plus stratégiques ;
- générer un fichier sitemap.xml (plan de site) et le soumettre à Google via la Search Console, ce qui peut occasionner une indexation express dans un délai de 24h ;
- avoir un site responsive ou mobile-first, car une partie des crawlers est uniquement dédiée à la version mobile des domaines explorés ;
- surveiller la vitesse de chargement de votre site web (y compris sur mobile) ;
- éliminer les contenus dupliqués et ceux de mauvaise qualité, ou du moins en détourner les bots d’exploration (voir comment ci-dessous) ;
- obtenir des liens issus d’autres sites web (backlinks) du même secteur d’activité, lesquels vous attireront non-seulement des crawlers, mais également du trafic et du link juice, ce qui augmente significativement vos chances de ranker sur des mots-clés intéressants !
Nota Bene : vérifiez régulièrement les rapports d’exploration disponibles sur la Search Console, et constatez l’évolution
Comment savoir si son site est bien indexé ?
En cas de doute, si vous avez de grandes difficultés à ranker, il suffit d’utiliser la commande « site: » de Google. Dans la barre de recherche, tapez la requête « site :www.votresiteinternet.com ».
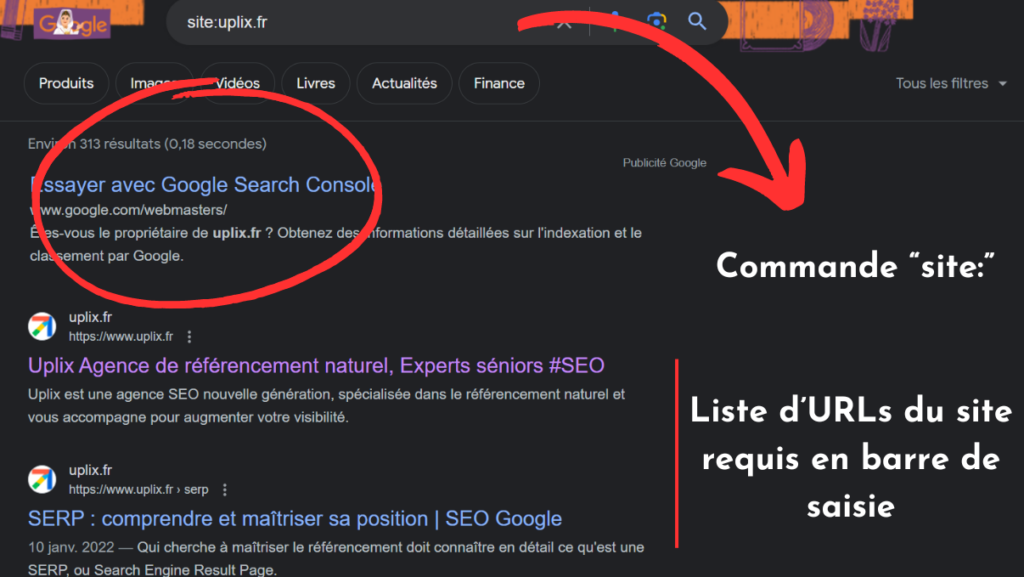
La SERP affichera alors la liste des pages connues du nom de domaine indiqué. Aucun résultat n’apparaît, c’est que l’indexation n’a pas encore eu lieu !
Comment éviter l’indexation de certaines pages ?
Il existe également moult manières d’informer les robots d’indexation que vous souhaitez laisser certaines pages désindexées. Bien sûr, l’option de la suppression est parfois valable, mais ce n’est pas toujours le cas : certaines pages en travaux, par exemple, auront simplement besoin d’un délai avant indexation. Ainsi, diminuez le nombre de pages indexables avec :
- le fichier robots.txt, situé à racine d’un site web et accessible via une adresse comme “https://votresiteinternet.fr/robots.txt”. Ce fichier donne des instructions aux crawlers, lesquels peuvent néanmoins outrepasser certaines indications ;
- les balises meta robots, généralement situées dans la balise <head> d’un document HTML. Elle peut servir à donner une instruction relative à l’indexation et au suivi des liens internes d’une page web ;
- les entêtes HTTP X-Robots Tag, moins pratiques à mettre en place que les balises meta robots ;
- la balise canonical, principalement utilisée en cas de duplication de pages. Elle spécifier la version de la page qui doit être indexée, mais cela ne sert que dans certains cas particuliers (souvent en e-commerce…) ;
- la redirection 301, particulièrement utile lors d’un processus de migration, d’une refonte ou même d’un changement d’arborescence. Elle permet de garder le trafic et le link juice engendré par des pages obsolètes en les injectant vers de nouvelles URLs ;
- Le code « 410 Gone », qui permet une désindexation assez rapide des ressources que vous souhaitez rendre définitivement indisponibles.
Pour finir…
L’indexation est une phase indispensable du référencement naturel mais bien évidemment insuffisante pour faire ranker vos pages sur des mots-clés stratégiques. Néanmoins il faut absolument s’assurer que cette étape se déroule sans encombres en éliminant l’ensemble des facteurs bloquants et ainsi de garantir la prise en compte de l’ensemble de ses pages importantes.
Si l’indexation prend du temps, commencez par corriger les défauts de votre site web plutôt que de vous ruer sur la Search Console pour forcer le processus. Il en va de la suite des opérations SEO, dont les bénéfices mettront de toute façon du temps à advenir.
Et si jamais vous êtes complètement perdu, même après la lecture de cet article, n’hésitez pas à demander conseil auprès d’une agence de référencement naturel !
