
Mis à jour le 31/03/2025
Le budget crawl est un terme bien connu des référenceurs mais encore très obscur pour de nombreuses personnes.
Avant d’indexer et d’afficher des pages en résultats, les moteurs de recherche comme Google procèdent à une étape au préalable. Cette étape, essentielle au SEO et au bon fonctionnement des moteurs de recherche, est le crawl. Le crawl consiste en l’exploration par des robots (comme Googlebot ou Bingbot) des pages web d’un site pour les référencer et les classer selon des critères de qualité définis par l’algorithme.
Le budget crawl (ou budget d’exploration) représente le temps passé par un crawler sur un site web et le nombre de pages qu’il y explore chaque fois qu’il se rend dessus. Il sert notamment à mieux répartir la présence des bots sur les sites. Cela permet à la fois de ne pas saturer les serveurs par leur simple présence, mais également de ne pas s’attarder sur certains domaines au détriment d’autres, peut-être plus qualitatifs.
Si la plupart des sites web ne sont pas directement concernés par le budget crawl dans leur SEO, certains d’entre eux doivent y accorder une importance particulière. À ce titre, le budget crawl est loin d’être égal pour tous les sites web. Il existe un certain nombre de variables que nous évoquerons plus avant.
La “Crawl rate limit”, c’est quoi ?
Le taux limite de crawl désigne la vitesse d’exploration des bots, qui représente le nombre de requêtes envoyées au serveur chaque seconde. Un site performant va pouvoir recevoir une forte intensité de crawling et donc laisser sprinter les Googlebots (ou Bingbots, etc.) sans que sa bande passante ne s’en trouve saturée, ce qui augmenterait le temps de chargement pour les internautes et dégraderait ainsi leur expérience de navigation.
A contrario, un site assez lent va avoir du mal à répondre à toutes les requêtes des bots, ce qui ralentira même le travail des crawlers. Aussi les algorithmes sont-ils conçus pour adapter leur vitesse d’exploration afin de maximiser le nombre de pages visitées à la seconde sans mettre le serveur en difficulté.

Néanmoins, il peut arriver que leur ajustement ne soit pas suffisant pour soulager le site web crawlé. Dans ce cas, le webmaster peut fixer une limite maximale de vitesse d’exploration, via la Google Search Console. Il ne peut, en revanche, inciter les algorithmes à passer plus vite sur son site web. De même, le bot peut décider de ne pas atteindre la vitesse limite fixée par le webmaster.
L’impact du budget crawl sur le SEO
Vous l’aurez compris : le budget crawl a un impact certain sur le SEO et influence grandement le référencement des pages d’un site web. Par exemple, un budget crawl insuffisant entraînera un retard dans l’actualisation du contenu d’un site. L’ajout de nouvelles pages peut être omis, conduisant à une exploration et une indexation tardives.
Une exploration efficace, et donc un référencement optimisé des pages web d’un site, passe donc nécessairement par un budget crawl lui aussi efficace. Les robots de Google doivent impérativement explorer le contenu et les liens qui apportent de la valeur ajoutée à un site web.
Une chose importante est également à prendre en considération lorsque l’on évoque le budget crawl dans le SEO : l’exploration en elle-même n’a pas d’impact sur votre positionnement Google. En effet, le positionnement est déterminé une fois que l’exploration est effectuée, en fonction du page rank notamment. Toutefois, une exploration insuffisante ou des erreurs d’exploration peuvent expliquer un moins bon positionnement voire une absence d’indexation pour les pages moins explorées.
Quels sites doivent se préoccuper du Budget Crawl ?
La plupart des sites web n’ont, de manière générale, pas à se soucier du budget crawl pour le référencement de leurs pages. Il existe néanmoins deux exceptions notables :
- Les sites récents, qui, par définition, ne sont pas encore populaires. Les robots de Google peuvent dans un premier temps moins explorer ces sites et ne pas indexer toutes les pages et URLs indexables.
- Les sites web comportant plusieurs milliers d’URL : le taux limite de crawl peut dans certains cas empêcher l’exploration de certaines pages. Il faut donc impérativement pour les sites concernés optimiser le budget crawl pour permettre au contenu visant à être exploré par Googlebot de l’être.
S’il est nécessaire d’optimiser son budget crawl, cela est notamment lié à l’impact qu’a le budget crawl sur le SEO.
Quels facteurs affectent le budget de crawl ?
Le budget de crawl de votre site dépend de multiples variables, à commencer par ses performances, la quantité et la qualité de son contenu, mais aussi tout bonnement sa popularité (trafic, backlinks, etc.). Pour ne pas vous faire surprendre, voici quelques points clés à surveiller de près.
Les liens brisés et autres pages d’erreur
Les liens brisés (erreur 404) et toute autre page inutile comme du contenu obsolète, consomment un budget crawl inutile. Plus votre site est de grande taille, plus vous avez de chance d’accumuler ce type de pages, considérées par les experts SEO comme une véritable réserve de budget crawl. Pour l’exploiter, il s’agira de supprimer le plus de pages possibles, ou bien de faire en sorte qu’elles ne soient pas visitées par les bots.
Quoi qu’il en soit, pour les trouver, vous pouvez vous servir de la Search Console ou d’outils SEO plus avancés comme Oncrawl, ou Majestic SEO.
Les crawlers traps
Les pièges à crawlers sont, en quelque sorte, la version amplifiée du problème précédent. C’est quand toute une partie de votre site web se transforme en labyrinthe pour le Googlebot, à cause d’un nombre conséquent d’URLs sans pertinence pour votre SEO, situés à une profondeur absurde et/ou générant des boucles de redirections qui l’empêchent de se diriger vers vos pages stratégiques.
Cela peut arriver pour des raisons très diverses, comme un nombre important de chargements de scripts JavaScript, ou un paramétrage des URLs défaillant.
Les problématiques de contenu
On l’a dit, les bots réagissent à votre contenu. Ils sont sensibles à des signaux très simples et faciles à modifier. D’abord, la fréquence de publication et de mise à jour est déterminante. En effet, mettons que les algorithmes passent 3 fois par semaine sur votre site internet, et qu’ils n’y détectent aucun changement. Dans ce cas de figure, ils risquent fort de passer de moins en moins souvent. À l’inverse, si vous modifiez plus souvent votre contenu, la fréquence des visites peut augmenter petit à petit.
Votre site doit donc être entretenu et mis à jour régulièrement pour qu’il paraisse qualitatif aux yeux de Google. L’ajout de nouvelles pages, et donc d’un contenu nouveau, augmentera la pertinence de votre site pour Googlebot. De plus, cela vous permet d’améliorer votre SEO de manière générale (en vous positionnant sur de nouveaux mots-clés, par exemple).

D’autre part, le contenu dupliqué interne ou simplement de mauvaise qualité va influencer négativement le travail des bots. En effet, votre budget crawl va se voir dilapidé sur des pages non stratégiques, en passant deux fois sur les mêmes contenus, ou bien en envoyant à l’index des informations désavantageuses pour votre site web. En somme, comme souvent en SEO, privilégiez la qualité à la quantité.
S’il est important d’avoir suffisamment de contenu pour la popularité d’un site, ce sont les pages avec du contenu qualitatif qui permettront à votre site de se démarquer. Le budget crawl sera mieux réparti avec du contenu qualitatif, et l’exploration des pages mieux effectuée.
Les défaillances techniques de votre site web
Concernant la partie technique de votre domaine, il faudra bien surveiller les temps de chargement de votre site web, quitte à changer d’hébergeur ou à utiliser un CDN. Pour tester et voir si vous avez besoin de réduire le temps de chargement de vos pages, utilisez Google Pagespeed. Encore une fois, si vous vous sentez perdus, une agence SEO pourra vous aiguiller sur la marche à suivre.
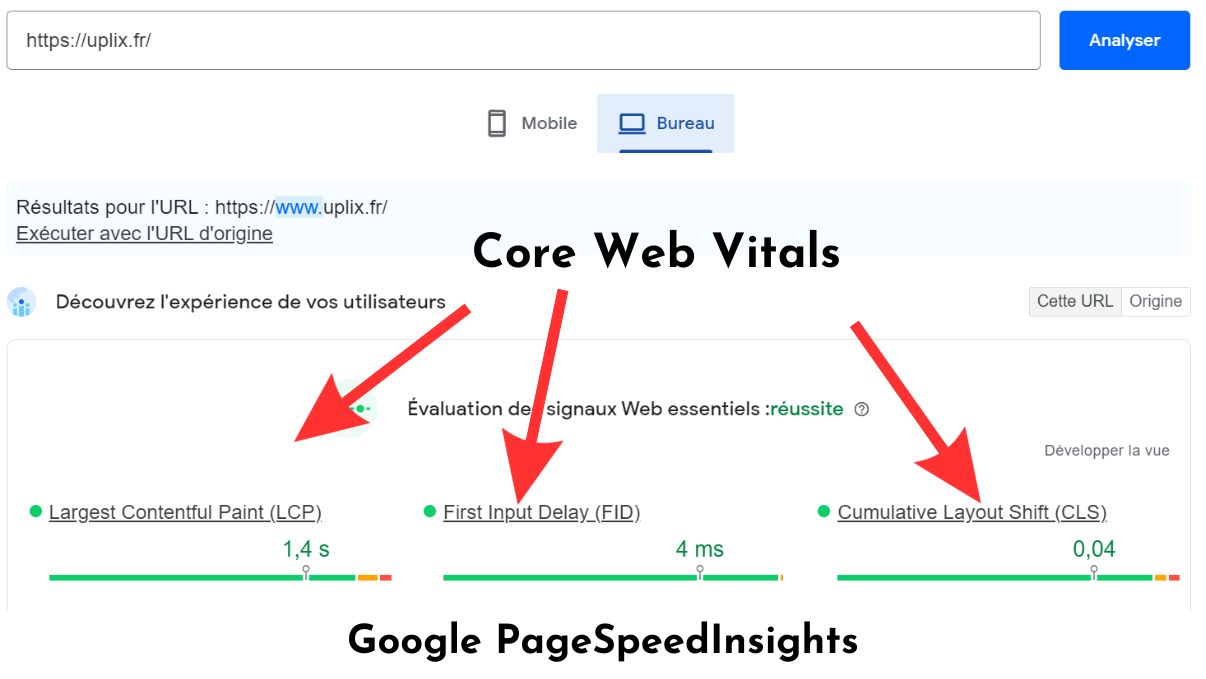
Enfin, il est primordial d’avoir un site web totalement responsive, voire mobile-first (conçu pour appareil mobile avant d’être adapté aux formats desktop). En effet, tout un escadron de crawlers est exclusivement dédié à la navigation mobile, et c’est en soi un très mauvais signal SEO que de n’avoir pas une version de site adaptée, plus grave encore que la question du budget crawl.
Quelles pratiques SEO pour un budget crawl optimal ?
Vous souhaitez entamer un chantier spécial “budget crawl” ? Outre le fait d’améliorer continuellement la qualité intrinsèque de votre site web, on vous énonce toutes les étapes nécessaires pour que celui-ci soit exploré dans les meilleures conditions possibles et indexé de sorte à apparaître le plus haut possible dans les SERPs !
Trouver les pages qui vous font perdre du budget crawl
Pour que votre site maintienne un budget de crawl optimal, Illyes recommande de ne pas gaspiller de ressources sur des URL à faible valeur ajoutée qui peuvent détourner l’activité de crawl de votre contenu de haute qualité. Illyes considère comme à faible valeur ajoutée des URLs comme :
- la navigation à facettes et les identifiants de session ;
- le contenu en double sur le site ;
- les pages « Soft 404 » ;
- les pages piratées ;
- les espaces infinis et les proxies ;
- le contenu de faible qualité et le spam ;
Pour vous pouvez également consulter la Search Console, afin de comparer le nombre de pages visitées avec celles qui ont été indexées. Si vous constatez un écart important, c’est qu’il y a probablement du gaspillage de budget crawl dans l’air. Pour vous en assurer et détecter les pages ou les zones du site qui posent problème, nous vous recommandons de contacter une agence SEO afin de procéder à une analyse de logs, une opération qui requiert des compétences techniques assez poussées.
Vous saurez alors exactement :
- le taux de crawl sur l’ensemble des pages de votre domaines ;
- quelles pages n’ont pas croisé de Googlebot depuis un moment ;
- quelles pages sont explorées régulièrement sans pertinence pour votre SEO.
La bonne nouvelle, c’est que les experts SEO sauront vous accompagner sur les manipulations à réaliser par la suite.
Diriger les algorithmes vers vos pages les plus importantes
Les algorithmes sont un peu comme des internautes numériques : ils ont besoin d’être guidés pour trouver les ressources essentielles de votre site web. Cela commence avec une arborescence de site cohérente et équilibrée en termes de profondeur de page. Avec une bonne répartition des silos et une hiérarchisation logique des pages mères et filles, vous pouvez arriver à un résultat satisfaisant. D’autre part, un maillage interne bien ficelé guidera les bots sur les pages les plus stratégiques.
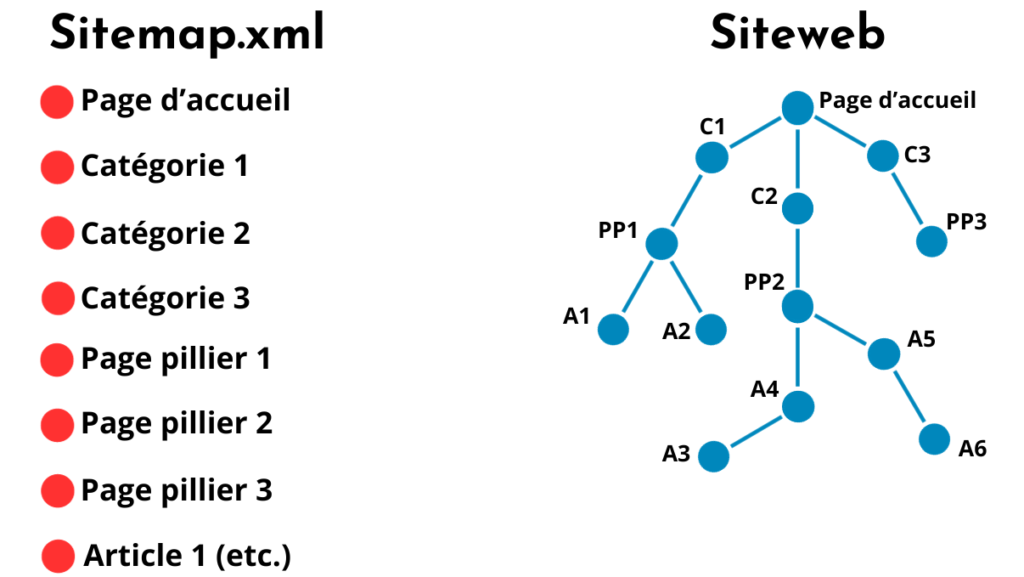
Si vous vous rendez compte que l’architecture de votre site est trop erratique, envisagez une refonte et retravailler la structure à partir d’un logiciel de mind map. Si vous n’avez que quelques modifications à effectuer, mettez bien à jour votre sitemap.xml, lequel aidera les bots à se repérer en amont de leur exploration.
Enfin, vous pouvez détourner les bots des pages inutiles avec un fichier robots.txt. Les fichiers robots.txt sont très pratiques : ils permettent d’indiquer aux bots les impasses de votre site web et de leur livrer des indications de crawl et d’indexation, afin de bloquer l’accès aux URLs non pertinentes.
Effectuer des demandes de crawl
Tous les sites internet ne bénéficient pas du même budget crawl. Si le vôtre reçoit assez peu les visites du Googlebot mais qu’il a récemment subi des modifications majeures, comme une refonte ou un ajout de pages assez important, il est recommandé de procéder à une demande d’exploration.
De cette manière, vous n’aurez pas forcément à attendre plusieurs jours (voire plusieurs semaines) pour que la version à jour de votre domaine soit indexée et donc disponible dans les SERPs.
Renseignez-vous au préalable sur la fréquence d’exploration de vos pages grâce à la Search Console. Si les crawls sont trop peu fréquents, lancez une demande manuellement :
- soit en envoyant directement les URLs à explorer ;
- soit en soumettant le sitemap.xml mis à jour, si les modifications sont trop nombreuses.
Quelle que soit la solution choisie, vous pouvez effectuer vos manipulations à partir de la Search Console, du moins en ce qui concerne le moteur de recherche Google.
Pour finir…
Le budget crawl est une notion SEO relativement avancée, qui demande de connaître quelques mécanismes des moteurs de recherche pour en saisir le fonctionnement. Sa bonne gestion influence directement la rapidité avec laquelle Google explore et indexe les nouvelles pages d’un site. Certains webmasters ne s’en préoccupent pas du tout, et finissent par se faire surprendre.
Leurs pages stratégiques optimisées aux petits oignons ne rankent jamais, simplement parce qu’elles ne sont pas explorées, le budget crawl étant dilapidé autrement. C’est pourquoi il est essentiel de vous soucier régulièrement de la bonne indexation de vos pages, en commençant par vérifier comment votre budget crawl est utilisé. Si vous remarquez des problèmes, les conseils ci-dessus et le recours à une agence SEO pourront vous être utiles.
