
Mis à jour le 31/03/2025
Le SEO, c’est un peu l’art de convaincre des machines, plus précisément les bots des moteurs de recherche. Mais, historiquement cette rhétorique informatique a pu entrer en conflit avec les besoins des internautes.
Prenons le concept de “mots-clés”, par exemple. Quand ils n’en étaient qu’à leurs balbutiements, Google, Yahoo et consort pouvaient considérer comme pertinent un texte comportant une densité de mots-clés telle qu’il en devenait illisible, pourvu que ce soit celui qui a été saisi en barre de recherche.
Autrement dit, SEO et UX n’allaient pas toujours très bien ensemble. Mais les temps ont changé, et les tours de passe-passe ont vu leur pratique perdre en intérêt, dont le cloaking, une technique de référencement estampillé Grey Hat ou Black Hat. De quoi s’agit-il exactement, et peut-on encore, malgré les risques, l’intégrer à une stratégie viable en 2024 ?
Qu’est-ce que le cloaking en SEO ?
Le terme “cloaking” signifie “camouflage”. Il permet de désigner une vieille technique SEO, qui consiste à présenter un contenu différent selon le type de visiteur que reçoit votre site web. Ainsi, une même page web n’affichera pas la même chose à un crawler qu’à un internaute humain.
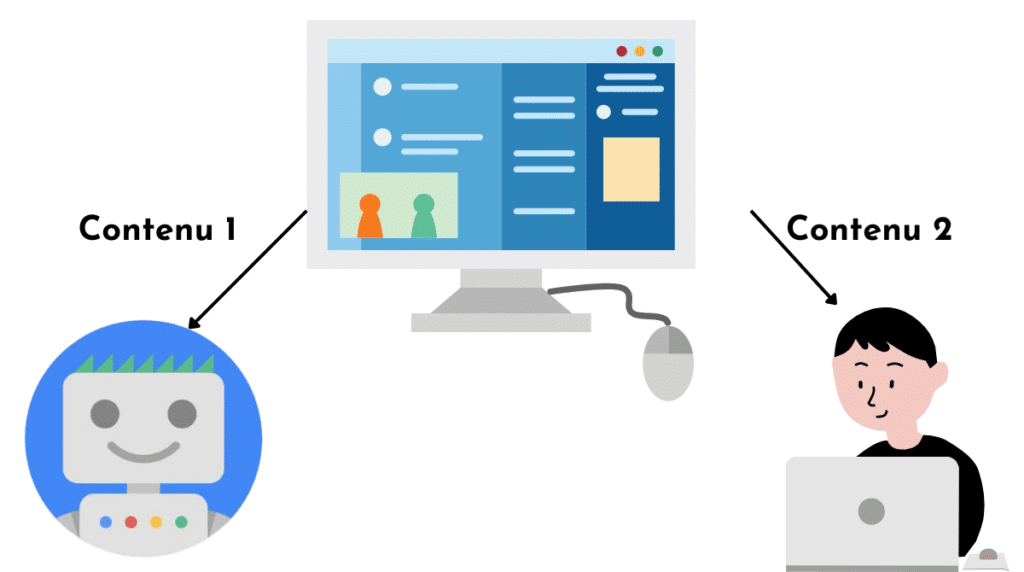
Cette pratique est censée présenter à des bots un contenu sur-optimisé (beaucoup de liens, de mots-clés, etc.) qui, dans la réalité, ne répondrait pas convenablement à un besoin humain. Ce leurre permettrait de mieux ranker dans les SERPs dans un premier temps, puis d’afficher la page normalement dès qu’un internaute en chair et en os se connecte à votre serveur.
Une tactique qui va à l’encontre de l’esprit des moteurs de recherche, lesquels ne peuvent plus juger de la qualité d’un contenu sur pièce. Alors est-ce que tout est bon à jeter dans le cloaking ? On va voir ça.
Comment fonctionne concrètement le cloacking ?
Que ce soit votre navigateur (Chrome, Mozilla, etc.) ou un crawler, tous ceux qui passent par un domaine envoient une requête HTTP qui inclut :
- le nom de la page web que vous demandez à voir ;
- le nom de domaine auquel elle appartient ;
- l’user agent (qui indique quel moteur de recherche ou navigateur effectue la demande) ;
- le referrer (à savoir le domaine d’où vous venez) ;
- votre adresse IP ;
Le serveur de site va générer (pour les sites PHP) ou afficher (pour les sites HTML) la page requise et la rendre lisible à votre navigateur.
Le cloaking peut alors se résumer en trois étapes :
- différenciation préalable des contenus à présenter : un dédié aux bots (optimisé SEO) et un dédié aux utilisateurs réels (optimisé UX) ;
- identification de l’origine de la demande via l’adresse IP ou les en-têtes HTTP qui révèlent l’user agent ;
- affichage du contenu approprié grâce à l’utilisation d’un langage côté serveur.
Les différentes techniques de cloaking en référencement
Il existe diverses manières de camoufler des pages, plus ou moins risquées…
Le cloaking old school avec du texte invisible : la plus risquée
L’astuce la plus cheap, qui ne passe même pas par l’identification de la requête HTTP, consiste à placer sur la page des textes de la même couleur que le fond (noir sur noir, blanc sur blan, etc.). Invisibles pour les lecteurs (sauf s’ils le sélectionnent avec la souris), ils sont pris en compte par les bots pour déterminer la densité de mots-clés présents sur la page.
Une technique désormais sans intérêt, sachant que le keyword stuffing ne fonctionne tout simplement plus comme il y a quinze ans.
La technique avancée basée sur l’adresse IP de l’utilisateur ou le user agent
On l’a vu, les requêtes HTTP contiennent une adresse IP et un user agent. Le premier est une suite de chiffres notamment consultable dans vos analyses de logs, et le second indique par une suite de caractères dans l’en-tête HTTP quel navigateur ou moteur de recherche soumet la requête. Dans les deux cas, la technique consiste à détecter un Googlebot (ou Bingbot, etc.) et à adapter le contenu en conséquence.

Nota Bene : les webmasters peuvent ajouter une étape de vérification supplémentaire avec un reverse DNS, qui aide à identifier qui se cache derrière une adresse IP.
Les variantes de cloaking basée sur Javascript, Flash ou Dhtml
Tous les navigateurs compatibles avec JavaScript, Flash ou Dhtml recevront une version différente de ceux qui ont désactivé ces langages. Les bots indexeront la page courante et les visiteurs humains seront redirigés vers une page plus intéressante pour eux. Néanmoins, cette méthode est révolue, car le JavaScript est généralement activé sur la plupart des navigateurs.
Les risques encourus et les sanctions applicables par Google
S’il vous prend en flagrant délit de cloaking, Google se réserve le droit de punir ce manquement à ses conditions d’utilisation en ;
- vous administrant une pénalité manuelle ou algorithmique pouvant affecter l’ensemble de votre site web ;
- en engageant une procédure judiciaire à votre encontre, laquelle peut déboucher sur une amende, voire des dommages et intérêts.
Comment les cloakers se font attraper ?
Google ne rigole pas avec le cloaking : un service spécial a carrément été instauré pour que les webmasters attentifs puissent dénoncer une concurrence déloyale, ou que les utilisateurs puissent se plaindre d’un contenu trompeur. En outre, un escadron de bots se faisant passer pour des utilisateurs humains a été lancé pour détecter d’éventuels doublons, ou des lignes de code servant à identifier un user agent ou l’origine d’une adresse IP.

Ainsi, mieux vaut vous en tenir aux pratiques énoncées ci-dessous…
Le cloaking White Hat, ça existe ?
Depuis que les moteurs de recherche intègrent l’UX aux critères de référencement, la pratique du cloaking est de moins en moins justifiée. Néanmoins, la complexification technique des sites web, qui implique le mode responsive, l’ajout de contenus multimédias, des filtres et autres fonctionnalités plus ou moins interactives, peut conduire à certaines pratiques tolérées par Google, telles que :
- l’adaptation de la page selon les aptitudes du navigateur utilisé ;
- la personnalisation de certains contenus en fonction de l’adresse IP (publicités plus ciblées, contenus plus ou moins sensibles, etc.) ;
- ne pas révéler les mots-clés de ses pages à la concurrence (ce qui pourrait les aider à optimiser leur contenu afin de surclasser le vôtre) ;
- bloquer l’accès du site aux bots collecteurs d’emails ;
- réaliser des tests A/B pour évaluer les performances de plusieurs versions d’une même page (trafic, conversions, etc.) ;
- vérifier l’en-tête HTTP Accept-Language pour afficher une version de la page en fonction de la géolocalisation du visiteur ;
Toutes ces pratiques vont dans le sens d’un contenu de meilleure qualité, adapté à l’utilisateur, et ne relèvent donc pas d’une tentative de hacking des crawlers avec des versions trompeuses d’une page web..
Le cloaking et l’obfuscation de liens : deux techniques à ne pas confondre
On a tendance à associer l’obfuscation de liens au cloaking. Sauf que le premier est une technique de dissimulation, quand l’autre relève de la substitution. À ce titre, l’obfuscation de liens est davantage tolérée par les moteurs de recherche, car elle les oriente uniquement sur les pages intéressantes, ce qui, dans un sens, facilite leur travail d’indexation. Ainsi, on évite de gaspiller du budget crawl avec une page “Mentions Légales”, ou des formulaires.
Nota bene : l’obfuscation est réalisée côté navigateur à travers JavaScript ou le code HTML, tandis que le cloaking se joue côté serveur.
Pour finir…
Le cloaking pur et dur est en voie de disparition, laissant place à des pratiques plus légitimes, qui respectent l’authenticité d’une page vis-à-vis des crawlers. Néanmoins, si vous avez pour projet d’employer le cloaking ou un de ses dérivés comme l’obfuscation, nous vous recommandons de le faire avec l’accompagnement d’un expert SEO.
Car, outre sa capacité à mieux jauger les limites acceptables de cette technique, il saura évaluer l’intérêt de la mettre en œuvre alors que vous pouvez peut-être vous y prendre autrement. En effet, la plupart du temps, des optimisations UX normales, un contenu de qualité, un travail des balises meta et l’implémentation de données structurées devraient largement faire le job pour convaincre aussi bien les bots que les internautes !
