
Mis à jour le 31/03/2025
Le fichier texte appelé “robots.txt” a pour rôle de donner certaines indications aux crawlers des moteurs de recherche (Googlebot, Bingbot, etc.), entre autres celle de ne pas aller explorer certaines zones d’un site web. Ainsi, en arrivant sur un site, les crawlers passent d’abord par le fichier robots.txt, afin d’être avisés des autorisations d’exploration.
Le fichier robots.txt détient aujourd’hui plusieurs applications utiles pour le SEO, à partir du moment où l’on sait comment l’utiliser. En effet, les erreurs de manipulation sont relativement courantes, et peuvent tirer votre référencement vers le bas.
Par exemple, certains webmasters mal informés pourront demander la non-exploration de certaines zones de leur site internet, de sorte à endiguer l’indexation des URLs qui s’y trouvent. Or, l’absence de crawl n’empêche pas nécessairement l’indexation, surtout si les pages en question figurent déjà dans l’index ou si elles reçoivent des backlinks.
Utilisation du fichier robots.txt en SEO
Lorsqu’il a été créé en 1994, le fichier robots.txt servait avant tout à limiter le passage des bots d’exploration afin de ne pas surcharger les serveurs. En effet, interdire le crawl sur certaines parties d’un domaine revenait à limiter le nombre de requêtes envoyées par différents bots, afin de désaturer la bande passante.
C’est beaucoup moins le cas aujourd’hui, les serveurs étant de plus en plus performants. Désormais, parmi les autres cas d’usage, on trouve :
- l’optimisation du budget crawl (suivi sur la Search Console comme ci-dessus), à savoir le temps d’exploration dédié à un site par les moteurs de recherche – qui peut s’épuiser sur des contenus inutiles ou dupliqués ;
- indiquer l’emplacement du sitemap.xml, qui peut s’implémenter de différentes façons ;
- bloquer l’indexation uniquement sur certaines ressources non HTML et multimédias (images, PDFs, vidéos, tableaux excel, etc.), afin que seuls les internautes ayant effectué certaines actions y accèdent (formulaires, abonnements, etc.) ;
- bloquer l’exploration par certains moteurs de recherche en particulier.
Comment créer un fichier robots.txt ?
La place du fichier robots.txt est à la racine de votre site. Son URL doit donc se composer de la manière suivante :
https://www.uplix.fr/robots.txt
Il doit être encodé en UTF-8, avec des lignes séparées par CR ou LF (pour fluidifier l’exploration des crawlers), et sa taille ne doit pas dépasser les 512 Ko. Ensuite, le document doit respecter une certaine structure, à savoir :
- la première ligne dédiée aux user-agents (nom des crawlers et bots des moteurs de recherche), afin de savoir auxquels doit s’appliquer l’interdiction d’explorer ;
- les lignes suivantes donnent les directives aux user-agents ciblés ;
- si l’on veut donner d’autres indications à d’autres bots, on reprend à la ligne pour désigner un nouvel user-agent (et rebelote) ;
- on peut réserver la dernière ligne (ou la première) au sitemap.
Nota Bene : le nom du fichier robots.txt doit être rédigé tout en minuscule.
Quelques éléments de syntaxe pour vos fichiers robots.txt
Bien que tous les moteurs de recherche ne suivent pas exactement de la même manière la syntaxe avec laquelle vous créez vos fichiers robots.txt, vous pouvez, la plupart du temps, vous fier aux caractères qui suivent :
- / : en plus de séparer les zones mentionnées, le “/” peut apparaître seul juste après la consigne “Disallow” (voir ci-dessous). Il signifie alors que tout votre domaine est fermé aux crawlers jusqu’à nouvel ordre ;
- * : placée après “user-agent”, l’astérisque indique que tous les bots sont concernés par la consigne qui suit ;
- # : il permet d’introduire des commentaires destinés aux utilisateurs humains et ne donne aucune directive aux bots ;
- $ : derrière une indication comme “Allow” ou “Disallow”, elle désigne un ensemble d’URLs qui contiennent une séquence de caractères placée juste avant le dollar (ex : “Disallow: /promo/$”)
Quelles instructions peut-on donner dans un fichier robots.txt ?
Il existe 5 principales indications à utiliser dans un fichier robots.txt. Passons-les en revue !
1. Définir un User-agent
On l’a vu, choisir un user agent est la première étape pour créer un fichier robots.txt. Il suffit donc de rédiger en première ligne quelque chose de cet ordre :
User-agent : * (consignes suivantes adressée à tous les crawlers)
ou
User-agent : Googlebot (consignes suivantes adressée aux bots de Google uniquement)
Ensuite, retour à la ligne et place aux indications proprement dites !
2. Disallow : pour bloquer les crawlers
C’est la plus utilisée dans un fichier robots.txt : elle n’autorise pas les bots concernés à explorer certaines zones de votre site web, voire le site entier. Ainsi, on peut trouver :
Disallow : / (c’est site dans son ensemble qui ne doit pas être crawlé)
ou
Disallow : /labs/ (interdit l’accès aux URLs incluses dans le répertoire “labs”)
ou encore
Disallow : /https://www.uplix.fr/15-plugins-wordpress-seo.html (interdit l’accès à une page en particulier)
3. Allow : pour ajouter des exceptions
Lorsque l’on place tout un répertoire hors de portée des bots d’exploration mais qu’on aimerait laisser certaines pages ou sous-catégories libres d’accès, la directive Allow est très pratique !
Si on veut l’implémenter correctement, il convient de la placer avant la directive Disallow – excepté si on ne s’adresse qu’aux Googlebots.
Ainsi, l’on trouvera des fichiers robots.txt ressemblant à ceci :
User-agent : *
Allow: /labs/https://www.uplix.fr/15-plugins-wordpress-seo.html.html
Disallow: /labs/
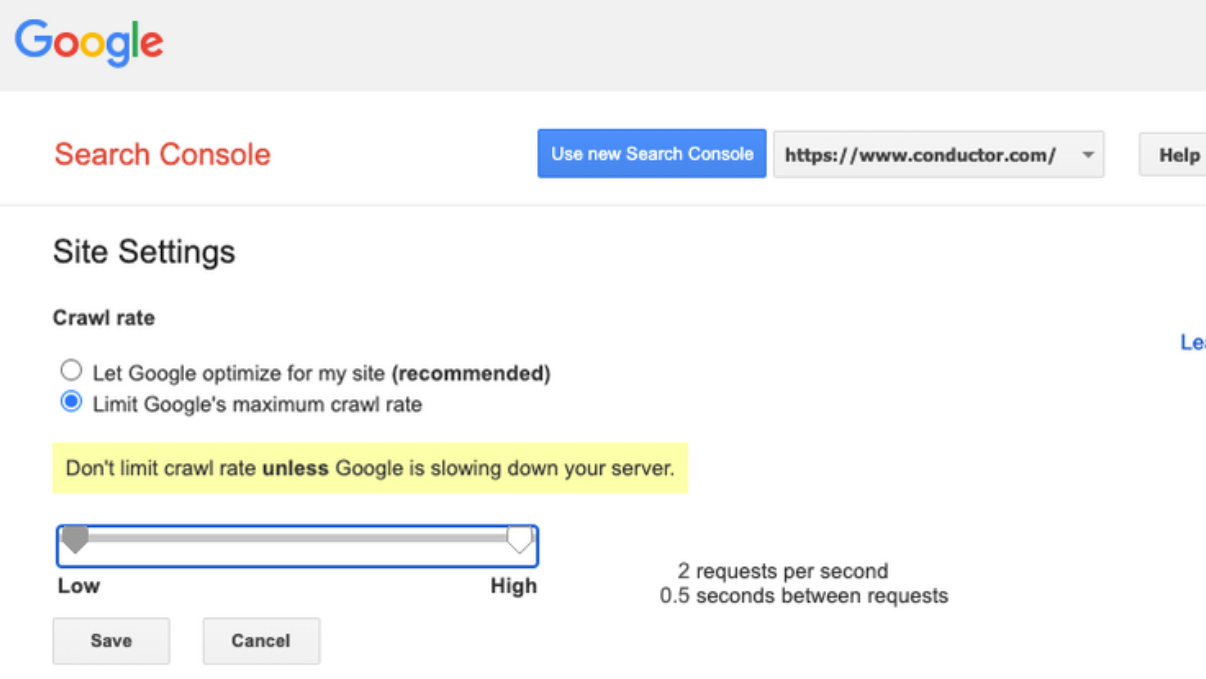
4. Crawl-delay : pour ralentir la vitesse des bots
Supportée par Yahoo, Bing ou encore Yandex, la directive Crawl-delay, qui limite la vitesse des crawlers, n’est pas prise en compte par Google. Il vous suffit de vous connecter à la Search Console, dans les Paramètres de vitesse d’exploration, pour modifier le nombre de requêtes envoyées à la seconde.
Concernant les crawlers impactés par le Crawl-delay, vous pouvez demander un intervalle d‘une ou plusieurs secondes entre chaque requête, par exemple :
User-agent: *
Crawl-delay: 2 (les robots espaceront leurs requêtes de 2 secondes).
5. Sitemap : pour donner directement l’adresse de votre plan de site
Si le (ou les) sitemap.xml de votre site est à jour (qui favorise le travail des bots et optimise ainsi votre budget crawl), n’hésitez pas à profiter de l’existence d’un fichier robots.txt pour indiquer son emplacement aux bots.
Comme sa présence ne dépend pas des user-agents, on peut placer la ligne un peu n’importe où. Idéalement, on la met tout au début ou à la fin (plus facile à trouver pour les humains !) de la manière suivante :
sitemap : https://www.uplix.fr/sitemap_index.xml
Placez-y autant de lignes que de sitemaps.xml mis à disposition des bots !
Comment générer automatiquement un fichier robots.txt ?
Pour exclure des crawlers de votre site directement depuis votre CMS, vous aurez besoin d’un plug-in SEO tel que Yoast SEO ou Rankmath.
Les deux solutions offrent leur propre éditeur de fichiers que vous pourrez utiliser non sans respecter la syntaxe et la structure décrites ci-dessus. L’intégration du fichier robots.txt se fera ensuite automatiquement !
Outils de test du fichier robots.txt
D’abord, vous pouvez simplement vérifier si un tel fichier existe sur votre site, et même y accéder en tapant l’URL principale du domaine en ajoutant “robots.txt” après l’extension. Par exemple :
https://uplix.fr/robots.txt
Hey oui ! Le fichier robots.txt est accessible aux bots comme aux humains ! Pour des tests plus approfondis, allez voir directement dans la Search Console, dans l’onglet “Exploration”. Vous trouverez rapidement une section intitulée “Outil de test du fichier robots.txt”.
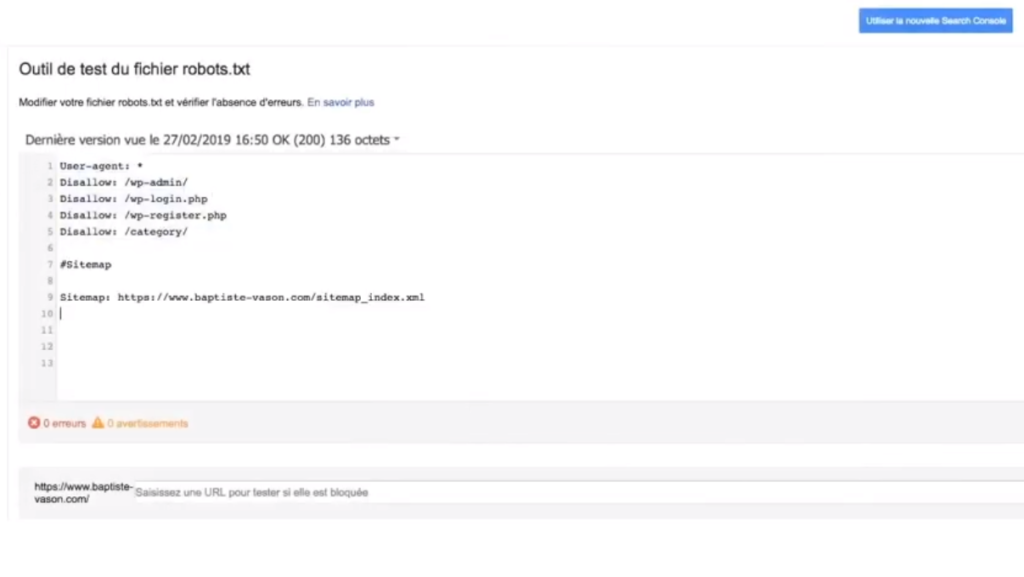
Il vous suffira d’y copier-coller tout le contenu de votre protocole d’exclusion, et de cliquer sur “Tester”. S’il y a des erreurs ou des imprécisions, la Search Console vous le fera savoir.
Pour finir…
Avant de nous quitter, sachez que les fichiers robots.txt ne vous prémunissent pas des bots malveillants, qui les ignoreront s’ils veulent infiltrer les pages de votre site web.
D’autre part, il est intéressant de savoir qu’un autre fichier existe sous le nom de human.txt, dont la fonction n’a rien à voir avec le fichier robots.txt. Il sert uniquement à mentionner les personnes qui ont contribué à l’élaboration du site. Une sorte de signature, en somme…
