
Mis à jour le 31/03/2025
Disponible sur tous les sites web, la balise meta robots est une courte ligne de code qui se situe dans l’entête HTML, et qui sert à donner des indications particulières aux bots des moteurs de recherche, notamment quant à l’indexation, le suivi de liens (internes ou externes) ou encore l’affichage dans les SERPs.
La balise meta robots permet donc de garder un certain contrôle sur le traitement de vos pages par Google, Bing ou autre. Néanmoins, il convient de l’utiliser avec parcimonie.
Comment intégrer la balise meta robots en code HTML ?
La balise meta robots se situe dans le head HTML, autrement dit entre les deux balises <head> et </head>. Niveau syntaxe (en XHTML ou HTML5), elle se présente comme ci-après :
<meta name= »robots » content= »consigne » />
Le terme “consigne” est remplacé par les instructions que vous laissez aux crawlers, comme “nofollow” ou “noindex”.

D’ailleurs, si vous souhaitez donner plusieurs directives aux robots des moteurs de recherche, il suffit de les séparer par une virgule, de la manière qui suit :
<meta name= »robots » content= »consigne A,consigne B » />
D’autre part, vous pouvez choisir à quel moteur de recherche vous adressez vos directives, en remplaçant le terme “robots” par le nom d’un user-agent, comme “googlebots”. Ce qui donne alors :
<meta name= »googlebots » content= »consigne » />
Quoi qu’il en soit, l’intégration est facile à faire, à partir du moment où vous avez accès au code source d’une page.
Quelle différence entre la balise meta robots et le fichier robots.txt ?
Il existe un type de balise meta robots en particulier : la “noindex”. Tout comme le fichier robots.txt, elle permet de demander aux bots la désindexation d’une page web, autrement dit de faire en sorte qu’elle ne figure pas dans les possibles résultats affichés dans les SERPs.
La différence réside dans l’autorisation d’accès aux pages désindexées par les crawlers. Si vous voulez permettre aux bots de naviguer sur l’entièreté de votre site internet sans pour autant tout indexer, placez une balise meta robots noindex sur les pages concernées.
En revanche, si vous voulez que les moteurs de recherche passent tout bonnement leur chemin sans consulter votre page, bloquez-la complètement dans le fichier robots.txt.
Nota Bene : pour des pages web qui ont déjà été indexées une fois sur les moteurs de recherche, utilisez toujours une meta noindex, car si Google, par l’effet du robots.txt, ne consulte pas votre page, il ne se mettra pas à jour et ne désindexera pas le groupe de pages visées.
Quelle différence avec la balise X-robots-tag ?
Contrairement à la meta robots, la balise x-robots-tag peut intégrer l’entête HTTP, et peut moduler l’indexation de certains éléments seulement, comme des fichiers non html (images, vidéos, etc.). Elle est donc plus flexible que la meta robots, et peut servir quand votre CMS ne vous donne pas accès au code HTML.

Par ailleurs, la x-robots-tag ne sert pas qu’à la désindexation : elle aussi permet de poser d’autres directives, comme nosnippet ou notranslate.
Quelles sont les valeurs possibles pour la balise meta robots ?
Comme vu un peu plus haut, la balise meta robots permet de donner diverses consignes aux moteurs de recherche. Les plus utilisées sont les suivantes (liste non-exhaustive) …
Index et Noindex
On a déjà comparé la balise noindex avec le fichier robots.txt. On a vu qu’elle désindexait la page ciblée sans en empêcher le crawl. Dans tous les cas, faites bien attention aux pages que vous souhaitez désindexer : une erreur aurait des conséquences délétères sur votre référencement.
Attention néanmoins : à la différence de Google, certains moteurs de recherche n’interprètent pas la directive “noindex” comme une demande de désindexation.
Enfin, la directive “index” permet aux robots de bel et bien indexer vos pages. Comme cette valeur est appliquée par défaut, rares sont les cas où elle vous sera utile.
Follow et Nofollow
Ces valeurs font partie des plus importantes, car elles impliquent la notion de linkjuice. En gros, plus une page a de la valeur dans le PageRank de Google, plus son “jus de lien” est important.
Or, quand cette page contient des redirections, internes comme externes, elle distribue le linkjuice en le partageant, mais pas nécessairement de manière équitable.
En conséquence, si vous avez placé un lien vers votre propre site pour bénéficier des effets vertueux du maillage interne, et aussi des liens externes (pointant vers un site tiers) vous pouvez perdre une partie du précieux linkjuice que vous souhaitez irriguer en priorité au sein de votre domaine.
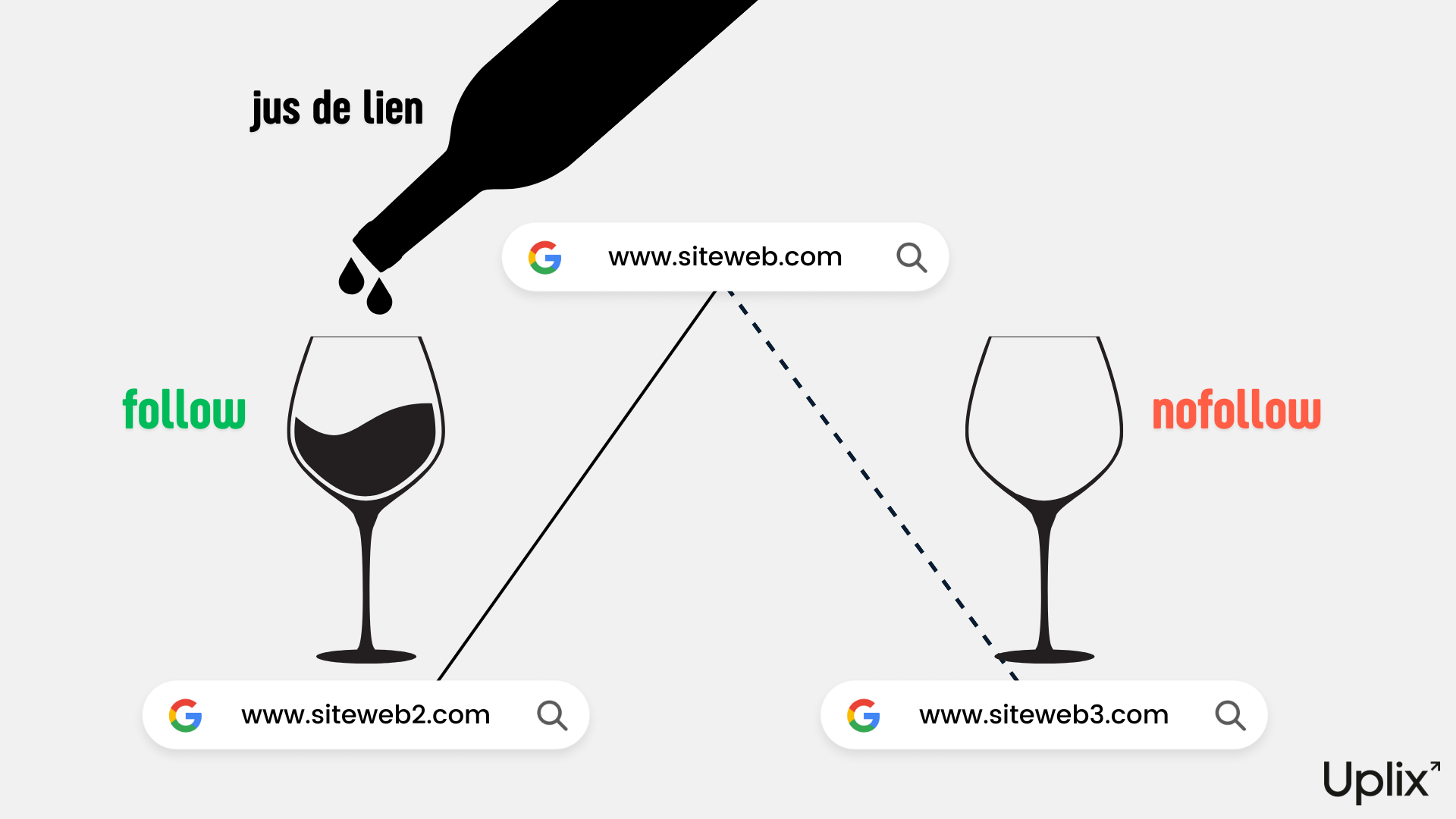
D’un autre côté, n’avoir aucun lien en follow n’est pas forcément valorisé par Google. C’est pour cela que certains experts SEO sont très attentifs à mettre leurs liens en follow ou nofollow.
Nota bene : la balise nofollow empêche le suivi sur tous les liens de votre page.
Noarchive et nocache
La valeur noarchive demande au robot de ne pas laisser aux internautes l’accès à une version en cache de votre page web, c’est-à-dire la dernière version indexée et conservée par Google même si le contenu a été retiré.
En général, cette balise sert aux webmasters qui veulent passer du contenu gratuit en privé, et demander un abonnement payant pour sa consultation en ligne.
Attention : vous ne pourrez plus savoir la date de la dernière indexation de votre page ; uniquement celle du dernier crawl, dans le cas où vous procédiez à une analyse de logs.
Enfin, la valeur nocache sert exactement à la même chose, mais s’applique exclusivement à Bing.
Pour finir…
Bien que simple à mettre en place, la balise meta robots est un outil avancé de stratégie de référencement naturel. Nous vous recommandons vivement de faire appel à un expert SEO avant d’utiliser une de ces valeurs, car on peut toujours se faire prendre au piège par une subtilité.
À titre informatif, sachez qu’il existe nombre d’autres valeurs non-listées ci-dessous, comme :
- nosnippet
- max-snippet
- unavailable_after
- notranslate
- max-image-preview
- max-video-preview
Comme ça au moins, si vous voulez creuser le sujet, vous avez les refs !
