
Mis à jour le 03/04/2025
Le “scraping” (to scrape ; “gratter” ou “racler”), à ne pas confondre avec scrapping (to scrap ; “abandonner” ou “se débarrasser de”) est un terme utilisé pour évoquer le fait de récolter des informations sur un site internet à des fins de stratégie marketing ou SEO. Il peut s’agir de récupérer quasiment n’importe quoi, à savoir :
- du contenu (texte, images, vidéos, code, etc.) ;
- des mots-clés ;
- des liens hypertextes ;
- des contacts (adresses, mails, numéros de téléphone) ;
- des offres (prix, produits, promotion) ;
- etc.
Cette forme avancée de veille permet d’analyser un certain nombre d’éléments qui sous-tendent l’activité de votre secteur, et de peaufiner votre propre stratégie de business et de présence digitale à travers l’analyse et l’exploitation légale des données obtenues.
Scraping vs crawling : quelle différence ?
Le crawling signifie l’exploration d’un site, tandis que le scraping désigne l’extraction de données. La différence réside dans le fait que l’exploration sert à découvrir un domaine via ses différentes pages, son maillage interne et ses hyperliens avec d’autres sites. Cela vous renseigne sur sa structure générale et sur sa popularité.

Avec le scraping, vous récupérez un ensemble d’informations que contiennent ces pages et l’enregistrez sur un support pour l’analyser dans un second temps. À noter que le scraping ne va pas sans le crawl d’un site web, ne serait-ce que pour sélectionner les URLs qui vous intéressent.
À quoi sert le Scraping en SEO ?
Avec le scraping, on cherche à se constituer une solide base de données sur les plateformes concurrentes et les prospects qui circulent sur la toile. On cherche notamment à :
- analyser des pages bien positionnées sur certains mots-clés ;
- surveiller les prix que pratique la concurrence ;
- analyser la stratégie sémantique d’un site à travers les méta-données (titres, méta-descriptions, liens internes et externes, balises HTML) ;
- trouver du contenu dupliqué ;
- être à jour sur les modifications de contenus et de fonctionnalité des sites de votre secteur ;
Exemple simple de scraping : Google collecte des données auprès des comparateurs de prix touristiques afin de présenter à ses utilisateurs les prix des vols et des hôtels.
Le scraping, comment ça marche ?
D’abord, il va s’agir de cibler les ressources que l’on veut scraper, en se fixant des objectifs clairs (popularité, conversions, etc.). Ce n’est qu’à partir de l’identification du besoin que l’on choisira de scraper :
- des sites concurrents (pour une approche disruptive de votre business) ;
- des pages de forums ou de réseaux sociaux (pour comprendre le point de vue des prospects) ;
- des articles de référence sur une thématique précise (pour produire du contenu précis et exhaustif).
Une fois que l’on sait quelles ressources vont nous intéresser, on va recourir à l’une des deux grandes manières de scraper un site :
- le scraping manuel, qui consiste à copier-coller des données sur un document annexe. C’est la technique la plus simple, mais également la plus lente, qui ne vaut que pour une faible quantité d’informations ;
- le scraping automatique, qui consiste à se servir d’outils tels que des robots scraper ou un programme informatique qui va crawler le domaine pour en récupérer les datas qui nous intéressent.
Quels sont les différents types de scraping ?
Il existe plusieurs manières de classer le scraping. En premier lieu, on peut procéder selon le besoin qu’il sert, à savoir :
- le scraping de contenu, qui va notamment aider à en générer d’autres, améliorés ou traités sous un angle différent ;
- le scraping de contact, qui va récupérer des adresses électroniques, des numéros de téléphones, et autres datas du genre ;
- le scraping de prix, autrement dit une veille tarifaire sur les e-boutiques ;
- etc.
Mais l’on peut également distinguer :
- le screen scraping, qui consiste à extraire des contenus depuis un écran (courant dans la sphère des applications bancaires) ;
- le report mining, qui récupère les données d’un rapport sous forme de fichier texte (ce que font les data scientists avec de gros volumes de données) ;
- le web scraping, qui consiste à récupérer les infos directement sur un site web, et que l’on va détailler plus avant.
Les différentes étapes du scraping
Le scraping observe toujours les trois étapes suivantes :
- le fetching, c’est-à-dire le recensement des URLs à scraper, suivi de la récupération de leur code HTML et des éléments CSS ou JavaScript, avant de les analyser pour de bon ;
- le traitement des données que l’on brigue au moyen de sélecteurs CSS ou XPath pour une meilleure précision ;
- le stockage des données, à savoir l’exportation, la structuration et la sauvegarde des informations obtenues sur le support de votre choix, généralement sous forme de feuille de calcul (CSV ou Excel), ou autres formats plus avancés (JSON et REST), afin de les rendre plus lisibles.
Quels sont les principaux avantages du scraping ?
Si le scraping est particulièrement intéressant, c’est parce qu’il permet aux webmasters d’obtenir de façon automatisée un certain nombre de renseignements utiles à la mise en place d’une stratégie de présence digitale. On va notamment pouvoir :
- analyser les entreprises du secteur (datas linkedin, recrutements, avis, offres, contacts des employés à travers un pattern de type “nomprenom@entrepriselambda.fr”, etc.) ;
- attribuer des scores CRM (un indicateur de rentabilité) à des clients ou prospects ;
- mettre à jour les données dont on dispose et les rendre facilement opérationnelles.
- réutiliser du contenu après vérification, modifications et reformulation.
Quelles sont les limites du web scraping ?
Hélas, tout n’est pas rose avec le scraping, puisque :
- les sites ciblés peuvent tenter de bloquer l’adresse IP du scraper ;
- les contenus dynamiques JavaScript ou AJAX peuvent s’avérer difficiles d’accès ;
- il convient de veiller à ne pas outrepasser les limites de la légalité.
En somme, selon les sites visés par le web scraping, on peut se retrouver avec des lacunes dans les datas, ce qui, dans le pire des cas, peut fausser les analyses. En outre, il est facile de verser dans le Black Hat SEO en procédant purement et simplement à du vol de contenu (duplicate content). Néanmoins, il est possible de scraper sans nuire, à la manière d’un certain Google, qui reste à ce jour le plus gros scraper, ne serait-ce qu’avec son fameux Knowledge Graph ?
Comment limiter le scraping des sites concurrents ?
Si vous-même redoutez le scraping de la part des propriétaires d’autres sites web, vous pouvez leur mettre des bâtons dans les roues avec :
- le CAPTCHA, qui permet de distinguer les utilisateurs humains des bots. Une technique courante qui consiste à faire passer un test que seul un humain peut réussir, mais cela peut également nuire à l’expérience utilisateur ;
- la limitation du nombre de requêtes sur une période donnée pour chaque adresse IP, ce qui condamne les bots à réduire leur vitesse de crawl à celle d’un humain, au lieu d’explorer 50 pages à la seconde ;
- la modification régulière de la balise HTML, ce qui complique la tâche des scrapers qui s’appuient sur les schémas du balisage HTML.
Quels sont les principaux outils de Scraping ?
À présent, prenons l’angle opposé, et intéressons-nous à quelques logiciels de scraping souvent utilisés par les experts SEO et marketing :
- Captain Data : qui permet de récupérer les données les plus utiles pour vous sur les sites à forte autorité, mais également les réseaux sociaux. Il permet même d’envoyer des demandes de connexion sur LinkedIn, détecter des contacts et les enrichir, etc. Néanmoins, l’abonnement est de 100 €/mois ;
- TabSave, qui fonctionne de pair avec LinkClump, idéal pour scraper une banque d’images ou de fichiers sur le web, en récupérant tous les liens redirigeant vers des photothèques et autres, avant de télécharger une quantité considérable les fichiers.
- Scrapy, plus intéressant si on détient des connaissances en python et XPath ;
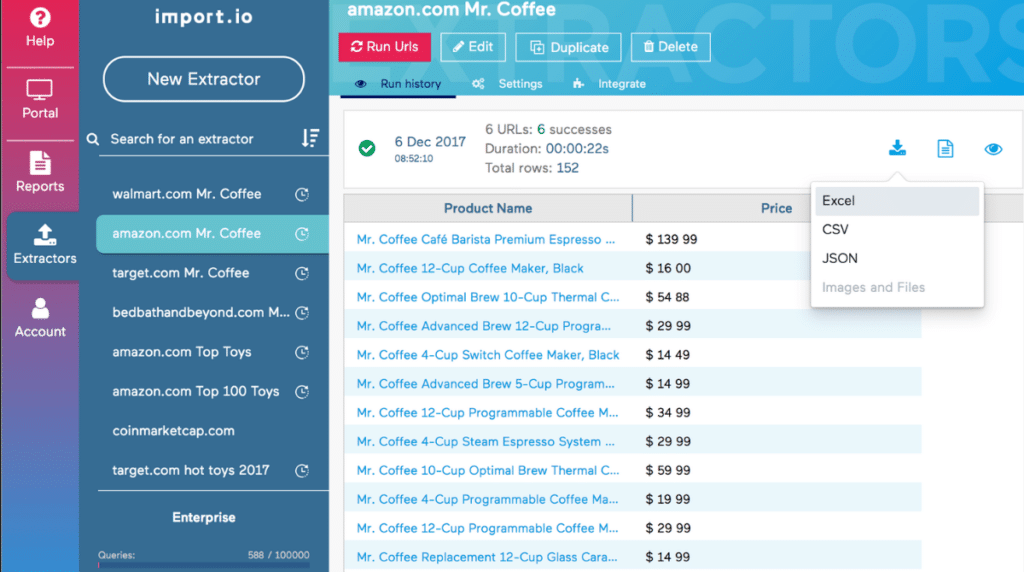
- Import.io, dont le concept d’extraction est fondé sur deux API : Magic et Extractor. Il va ainsi collecter les données à partir d’une liste d’URLs ou les datas spécifiques d’une page en particulier. Il est donc possible de procéder à une extraction à grande échelle, avec des résultats précis ;
- Apify : très bien pour scraper les sites d’e-commerce dans le cadre d’une veille concurrentielle (offres, produits, catégories, etc.) et lire vos données sur un tableau généré automatiquement ;
- Kimono, qui récolte des données à partir d’une liste d’URLs en se basant sur des scénarios définis au clic. Il s’utilise néanmoins avec une bonne maîtrise des langages HTML et JavaScript ;
- Web Scraper : plutôt axé débutants avec des vidéos tutorielles pour certaines tâches comme la pagination des contenus, les interactions, etc. ;
- DataMiner, une extension Chrome qui permet la récupération de contenus depuis les pages web que l’on visite ;
- Linkedin Sales Navigator qui explore les comptes de vos prospects sur LinkedIn ;
- Google Spreadsheets et XPath pour scraper les titres H2 des sites choisis (structures d’articles) mais aussi tout autre élément important des sites web.
Pour finir…
Le web scraping, s’il est bien fait et bien utilisé, permet d’avoir un coup d’avance sur la concurrence et sur les besoins de la clientèle. On peut même ralentir les tentatives de scraping sur son propre site web, avec la CAPTCHA, par exemple. Il faudra néanmoins réaliser une analyse fine des données obtenues pour réellement améliorer la qualité et la pertinence de votre site sans passer du côté Black Hat de la force SEO.
