
Mis à jour le 31/03/2025
DUST est l’acronyme pour Duplicate URL Same Text qui, en français, signifie : Différentes URLs avec Texte Similaire. C’est une forme assez précise et involontaire de Duplicate Content. En effet, il arrive qu’une même page web, avec un unique code source, soit accessible depuis plusieurs adresses URL. Cette problématique technique est courante, surtout chez les sites d’e-commerce (on y reviendra), et peut ralentir votre référencement naturel.
Uplix vous propose de voir ce qui engendre le phénomène de DUST, ses conséquences vis-à-vis des moteurs de recherche, et comment s’en prémunir efficacement dès aujourd’hui, quelle que soit la nature de votre site web !
Quelques exemples de DUST
Prenez le site d’Uplix et sa page d’accueil trouvable à l’adresse suivante : “https://www.uplix.fr/”. Dans certaines circonstances, vous pouvez vous retrouver avec des variantes comme :
- http://www.uplix.fr/
- http://www.uplix.fr
- https://uplix.fr/
- https://www.uplix.fr/index.php
- http://www.uplix.fr/index.php?source=emailing
Toutes ces URLs vous amènent à la même page, mais les quelques subtilités de syntaxe comme le slash à la fin de l’URL, le protocole HTTP, la présence des “www” sont considérées par les crawlers comme des pages différentes, au contenu parfaitement identique, donc dupliqué. Nous verrons plus avant ce que cela implique pour votre SEO.
Quels sont les différents cas de DUST ?
Comment se retrouve-t-on avec plusieurs URLs pour la même page ? Involontairement, qui plus est ? Il existe plusieurs situations pouvant engendrer ce phénomène.
Les URLs générées dynamiquement
Le cas le plus répandu est sans nul doute celui du e-commerce et des fiches produits qui composent les boutiques digitales. Il n’est en effet pas rare qu’un appareil ou un vêtement soit proposé en plusieurs tailles, coloris, etc. L’interface vous propose généralement un filtre à facettes pour choisir facilement les options qui vous intéressent, et ainsi affiner votre sélection.

Par exemple, vous souhaitez vous offrir un mini-lave-vaisselle, lequel se décline en de multiples coloris. L’utilisateur doit pouvoir naviguer de “bleu glacier” à “vert amande” sans avoir à changer de page, mais si le webmaster ne gère pas correctement leur paramétrage, il peut se retrouver avec autant d’URLs que de coloris :
- eboutique.com/minilavevaisselle/?colour=rose-pastel
- eboutique.com/minilavevaisselle/?colour=violet-chrome
- eboutique.com/minilavevaisselle/?colour=argent-perle
- eboutique.com/minilavevaisselle/?colour=lila-pervenche
- etc.
Ça peut aller très vite ! Et encore plus si plusieurs filtres peuvent s’appliquer sur une même catégorie d’articles. Mettons une boutique de vêtements qui vend des paires de sneakers :
- eboutique.com/sneakers/?colour=noir-40
- eboutique.com/sneakers/?colour=noir-42
- eboutique.com/sneakers/?colour=rouge-40
- eboutique.com/sneakers/?colour=rouge-42
- etc.
Chaque combinaison peut créer un nouveau lien que Google prendra pour une page dupliquée. Cela vaut également pour les pages traduites. À l’inverse, les URLs statiques ne génèrent pas de variations et ne contiennent pas de paramètres d’URL.
Nota Bene : on reconnaît assez aisément les URLs dynamiques, qui contiennent souvent des caractères comme : ?, &, %, +, =, $. Les filtres se situent généralement après un “?”.
Les Session IDs incluses dans les URLs
Quand les sites sont configurés pour garder une trace de ses visites et de l’activité des utilisateurs, ils attribuent à chacun un identifiant de session, avec une ID spécifique. Cela permet de reprendre plus facilement une conversion interrompue, comme la validation d’un panier. Or, pour garder cette session en mémoire une fois que l’internaute quitte la page, il faut bien la stocker quelque part.
C’est là qu’interviennent les fameux cookies : l’ID va simplement se greffer au navigateur de l’utilisateur, et ce dernier pourra reprendre son activité là où il en était. Néanmoins, si l’internaute a refusé l’usage de cookies pour des raisons de confidentialité, alors l’ID peut se voir transféré du serveur au navigateur en tant que paramètre joint à l’URL de la page.
À partir de ce moment-là, de nouvelles URLs sont créées pour chaque page visitée, ce qui occasionne un autre phénomène de DUST, lequel peut rapidement se multiplier avec le nombre de visiteurs qui font le choix de ne pas consentir au tracking.
Comment le DUST peut-il se répercuter sur votre SEO ?
On a détecté plusieurs problématiques liées au phénomène de DUST. Puisque les algorithmes associent la notion d’URL à une page unique et à son contenu (autrement dit, 3 URLs pointant vers une page X = 3 pages X), ils se retrouvent à :
- crawler plusieurs URLs et choisir lesquelles placer ou non dans l’index de Google ;
- diviser le PageRank d’une seule page sur plusieurs URLs ;
- mettre en concurrence plusieurs URLs pour une même page lors du classement dans les SERPs.
Tout ceci va présenter plusieurs inconvénients pour votre référencement…
Google pénalise-t-il les URL dupliquées ?
Non, car il ne s’agit pas d’une pratique Black Hat, c’est-à-dire une manipulation abusive des algorithmes. Au contraire, les webmasters font les frais d’une confusion de la part de la machine.
Pour autant, les moteurs de recherche sont bien obligés de traiter le phénomène en choisissant l’URL canonique (principale) pour éviter une cannibalisation avec ses variantes. Mais il se peut que l’URL sélectionnée ne soit pas celle qui vous arrange. Par exemple, vous pouvez perdre un paquet de backlinks pour l’autorité de votre page si certaines URLs sont déconsidérées.
Quels sont les effets néfastes concrets du DUST pour votre site web ?
Plusieurs effets pervers peuvent résulter du DUST, à savoir :
- une mauvaise répartition du budget crawl. Les crawlers qui parcourent les sites passent d’une URL à l’autre, et ils peuvent dépenser plus de ressources pour une seule et même page si elle détient plusieurs adresses. Dans le pire des cas, c’est prendre le risque de laisser inexplorées des pages plus importantes par simple épuisement du budget crawl ;
- un problème d’indexation, puisque le crawler peut exclure une version plus optimisée de votre page au profit d’une autre ;
- la dispersion de votre linkjuice obtenu, via divers backlinks, entre plusieurs URL. Il est hautement préférable de les plutôt concentrer sur une seule URL canonique, car le jus de lien est un facteur d’autorité puissant ;
- la dilution du PageRank ; cet algorithme qui attribue un score d’autorité à une page se voit fragmenté entre les duplicatas de l’URL et réduit la puissance des signaux de pertinence sur chaque page, ce qui les empêche toutes de supplanter la concurrence…
Certes, ces scénarios catastrophes se font rares, mais ils existent, et sont autant de freins possibles au ranking de vos pages, lesquelles perdent naturellement en visibilité dans les SERPs. Et comme le phénomène a souvent lieu sur des contenus stratégiques, parfois proches d’une conversion, les répercussions peuvent rapidement affecter votre chiffre d’affaires.
Comment détecter des Duplicate URLs, Same Text sur un site ?
Heureusement, il est devenu assez facile de se prémunir contre le DUST, et de le repérer rapidement lorsqu’il advient. D’abord en restant attentif aux signaux suivants :
- plusieurs de vos URLs affichent un contenu identique ou très proche ;
- les balises meta (title, metadescription, etc.) de plusieurs URLs sont similaires ;
- vos rapports d’indexation sur la Search Console indiquent une redondance avec des URLs très ressemblantes.
Néanmoins, on ne veut pas tout vérifier à la main, il y a beaucoup d’autres éléments à fignoler pour bien optimiser votre site web ! C’est pourquoi il existe des outils prêts à vous faciliter la tâche !
Quels sont les outils de vérification d’URLs dupliquées ?
Bien sûr, il y a l’opérateur de recherche “site:exemple.com intitle” associé à un mot-clé, lequel vous liste les URLs de votre domaine contenant ce mot-clé. Mais ça, c’est la vérification manuelle, si vous avez un doute. Outre cette technique, vous pouvez compter sur :
- SEO Review Tools, qui vous permet de saisir l’URL de votre choix pour obtenir le nombre de doublons qu’il y a dessus ;
- Siteliner, qui examine l’ensemble de votre domaine et dresse un rapport de liens dupliqués ;
- Screaming Frog lors d’une analyse de logs, afin d’identifier et d’analyser les problèmes de DUST en comparant directement les contenus des pages entre elles.
Que faire si l’on diagnostique un problème de DUST sur notre site web ?
Il existe plusieurs sortes de manipulations pour vous sortir d’un problème de Dust. En premier lieu, vous pouvez placer une balise noindex toutes les pages non principales, soit en <head>, soir dans l’en-tête HTTP. D’autre part, tous les liens internes qui pointent sur les URLs non canoniques doivent être supprimées ou changées afin qu’elles puissent conduire à la bonne adresse.
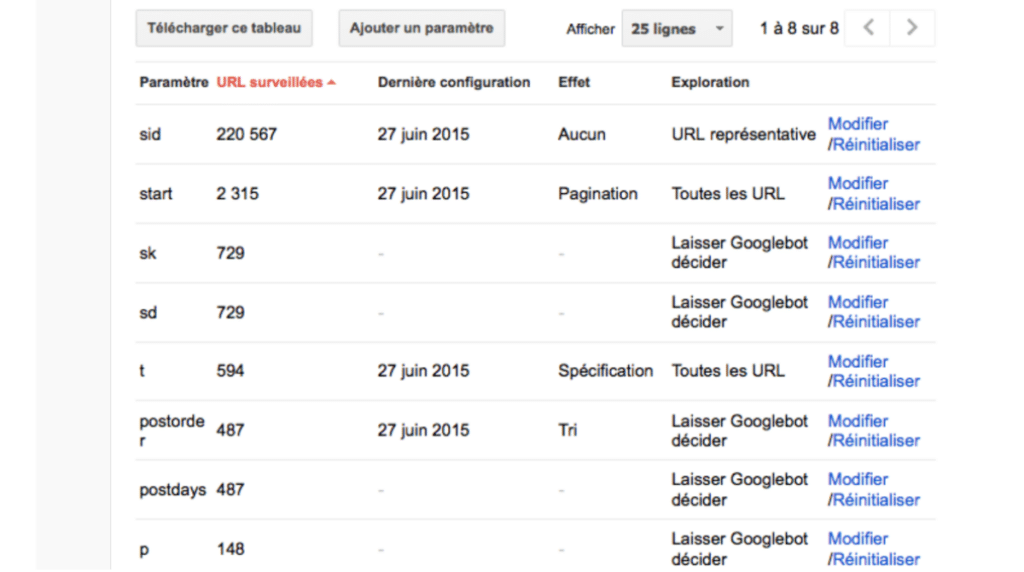
Vous pouvez également recourir à :
- la balise link rel= »canonical » pour indiquer aux moteurs de recherche quelle version d’une page est “la bonne”. Elle ressemble à ceci : < head > < link rel= »canonical » href= »https://www.uplix.fr » / > < /head >. Cela oblitère la problématique du Pagerank. En revanche, votre budget crawl est toujours gaspillé ;
- la redirection 301, qui redirige définitivement une URL vers une autre. De cette manière, le jus de lien ne se perd plus dans les doublons ;
- aux paramètres d’URL dans la Google Search Console (ci-dessus). Elle permet de demander aux bots d’ignorer les URLs non canoniques pour ne pas épuiser le budget crawl. Allez dans “Crawl” > “Configurer les paramètres d’URL” pour effectuer la manipulation ;
- à la déclaration des URLs passives, toujours dans la Search Console ;
- aux méta-robots, qui permettent d’ajouter au code HTML des balises Noindex et/ou Nofollow.
- une simplification de la structure des URLs afin de prévenir la création spontanée de DUST ;
Nota bene : pour les sites sous WordPress, le plug-in Yoast SEO peut vous faire gagner du temps, notamment en définissant par défaut une balise canonique pour toutes vos pages. Et si toutefois vous avez besoin de changer l’URL principale, vous pouvez toujours la configurer manuellement…
Pour finir…
Le DUST est un problème qu’on ne détecte pas tout de suite mais qui peut s’envenimer si on n’y prend pas garde. Heureusement, les difficultés SEO que le phénomène occasionne sont de plus en plus rares et minimes, mais attention tout de même à ne pas accumuler les erreurs techniques, surtout sur un site web de grande envergure !
Si vous détectez des URLs dupliquées à la lumière de cet article et que vous n’osez pas réagir, n’hésitez pas à contacter une agence SEO sénior comme Uplix, pour un audit express et un travail de balisage et de redirections sur-mesure !
